Disclaimer: I worked for 7 years at Mozilla and was Mozilla’s Chief Technology Officer before leaving 2 years ago to found an embedded AI startup.
Mozilla published a blog post two days ago highlighting its efforts to make the Desktop Firefox browser competitive again. I used to closely follow the browser market but haven’t looked in a few years, so I figured it’s time to look at some numbers:
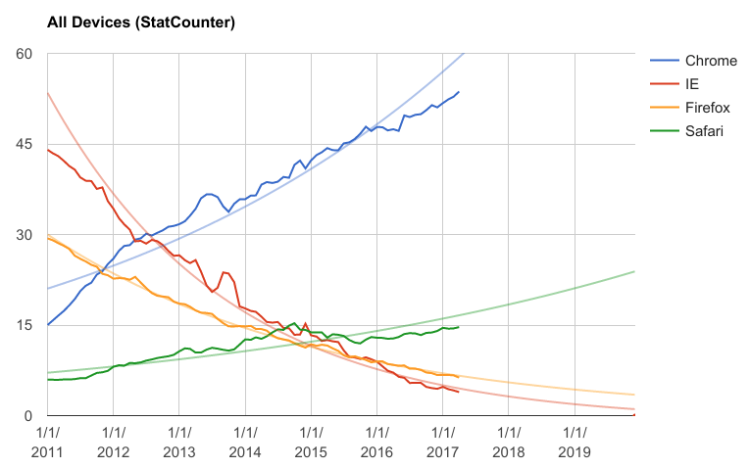
The chart above shows the percentage market share of the 4 major browsers over the last 6 years, across all devices. The data is from StatCounter and you can argue that the data is biased in a bunch of different ways, but at the macro level it’s safe to say that Chrome is eating the browser market, and everyone else except Safari is getting obliterated.
Trend
I tried a couple different ways to plot a trendline and an exponential fit seems to work best. This aligns pretty well with theories around the explosive diffusion of innovation, and the slow decline of legacy technologies. If the 6 year trend holds, IE should be pretty much dead in 2 or 3 years. Firefox is not faring much better, unfortunately, and is headed towards a 2-3% market share. For both IE and Firefox these low market share numbers further accelerate the decline because Web authors don’t test for browsers with a small market share. Broken content makes users switch browsers, which causes more users to depart. A vicious cycle.
Chrome and Safari don’t fit as well as IE and Firefox. The explanation for Chrome is likely that the market share is so large that Chrome is running out of users to acquire. Some people are stuck on old operating systems that don’t support Chrome. Safari’s recent growth is underperforming its trend most likely because iOS device growth has slowed.
Desktop market share
Looking at all devices blends mobile and desktop market shares, which can be misleading. Safari/iOS is dominant on mobile whereas on Desktop Safari has a very small share. Firefox in turn is essentially not present on mobile. So let’s look at the Desktop numbers only.
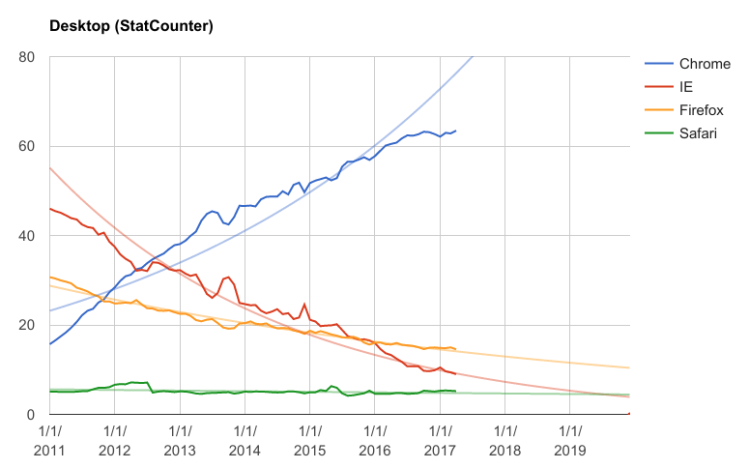
The Desktop-only graph unfortunately doesn’t predict a different fate for IE and Firefox either. The overall desktop PC market is growing slightly (most sales are replacement PCs, but new users are added as well). Despite an expanding market both IE and Firefox are declining unsustainably.
Adding users?
Eric mentioned in the blog post that Firefox added users last year. The relative Firefox market share declined from 16% to 14.85% during that period. For comparison, Safari Desktop is relatively flat, which likely means Safari market share is keeping up with the (slow) growth of the PC/Laptop market. Two possible theories are that Eric meant in his blog post that browser installs were added. People often re-install the browser on a new machine, which could be called an “added user”, but it comes usually at the expense of the previous machine becoming disused. It’s also possible that the absolute daily active user count has indeed increased due to the growth of the PC/laptop market, despite the steep decline in relative market share. Firefox ADUs aren’t public so it’s hard to tell.
From these graphs it’s pretty clear that Firefox is not going anywhere. That means that the esteemed Fox will be around for many many years, albeit with an ever diminishing market share. It also, unfortunately, means that a turnaround is all but impossible.
With a CEO transition about 3 years ago there was a major strategic shift at Mozilla to re-focus efforts on Firefox and thus the Desktop. Prior to 2014 Mozilla heavily invested in building a Mobile OS to compete with Android: Firefox OS. I started the Firefox OS project and brought it to scale. While we made quite a splash and sold several million devices, in the end we were a bit too late and we didn’t manage to catch up with Android’s explosive growth. Mozilla’s strategic rationale for building Firefox OS was often misunderstood. Mozilla’s founding mission was to build the Web by building a browser. Mobile thoroughly disrupted this mission. On mobile browsers are much less relevant–even more so third party mobile browsers. On mobile browsers are a feature of the Facebook and Twitter apps, not a product. To influence the Web on mobile, Mozilla had to build a whole stack with the Web at its core. Building mobile browsers (Firefox Android) or browser-like apps (Firefox Focus) is unlikely to capture a meaningful share of use cases. Both Firefox for Android and Firefox Focus have a market share close to 0%.
The strategic shift in 2014, back to Firefox, and with that back to Desktop, was significant for Mozilla. As Eric describes in his article, a lot of amazing technical work has gone into Firefox for Desktop the last years. The Desktop-focused teams were expanded, and mobile-focused efforts curtailed. Firefox Desktop today is technically competitive with Chrome Desktop in many areas, and even better than Chrome in some. Unfortunately, looking at the graphs, none of this has had any effect on market trends. Browsers are a commodity product. They all pretty much look the same and feel the same. All browsers work pretty well, and being slightly faster or using slightly less memory is unlikely to sway users. If even Eric–who heads Mozilla’s marketing team–uses Chrome every day as he mentioned in the first sentence, it’s not surprising that almost 65% of desktop users are doing the same.
What does this mean for the Web?
I started Firefox OS in 2011 because already back then I was convinced that desktops and browsers were dead. Not immediately–here we are 6 years later and both are still around–but both are legacy technologies that are not particularly influential going forward. I don’t think there will be a new browser war where Firefox or some other competitor re-captures market share from Chrome. It’s like launching a new and improved horse in the year 2017. We all drive cars now. Some people still use horses, and there is value to horses, but technology has moved on when it comes to transportation.
Does this mean Google owns the Web if they own Chrome? No. Absolutely not. Browsers are what the Web looked like in the first decades of the Internet. Mobile disrupted the Web, but the Web embraced mobile and at the heart of most apps beats a lot of JavaScript and HTTPS and REST these days. The future Web will look yet again completely different. Much will survive, and some parts of it will get disrupted. I left Mozilla because I became curious what the Web looks like once it consists predominantly of devices instead of desktops and mobile phones. At Silk we created an IoT platform built around open Web technologies such as JavaScript, and we do a lot of work around democratizing data ownership through embedding AI in devices instead of sending everything to the cloud.
So while Google won the browser wars, they haven’t won the Web. To stick with the transportation metaphor: Google makes the best horses in the world and they clearly won the horse race. I just don’t think that race matters much going forward.
Update: A lot of good comments in a HackerNews thread here. My favorite was this one: “Mozilla won the browser war. Firefox lost the browser fight. But there’s many wars left to fight, and I hope Mozilla dives into a new one.” Couldn’t agree more.
