Why building a better browser doesn’t translate to a better marketshare
I posted a couple weeks ago about Chrome effectively having won the browser wars. The market share observations in the blog post were based on data provided by StatCounter. Several commenters criticized the StatCounter data as inaccurate so I decided to take a look at raw installation data Mozilla publishes to see whether it aligns with the StatCounter data.
Active Firefox Installs
Mozilla’s public data shows that the number of active Firefox Desktop installs running the most recent version of Firefox has been declining for several years. Based on this data, 22% fewer Firefox Desktop installations are active today than a year ago. This is a loss of 16 million Firefox installs in a year. The year over year decline used to be below 10% but accelerated to 14% in 2016. It returned to a more modest 10% year over year loss late 2016, which could be the result of a successful marketing campaign (Mozilla’s biggest marketing campaigns are often in the fall). That effect was temporary as the accelerating decline this year shows (Philipp suggests that the two recent drops could be the result of support for older machines and Windows versions being removed and those users continuing to use previous versions of Firefox, see comments).

Year over Year Firefox Active Daily Installs (Desktop). The Y axis is not zero-based. Click on the graph to enlarge.
Obtaining the data
Mozilla publishes aggregated Firefox usage data in form of Active Daily Installs (ADIs) here (Update: looks like the site requires a login now. It used to be available publicly for years and was public until a few days ago). The site is a bit clumsy and you can look at individual days only so I wrote some code to fetch the data for the last 3 years so its easier to analyze (link). The raw ADI data is pretty noisy as you can see here:
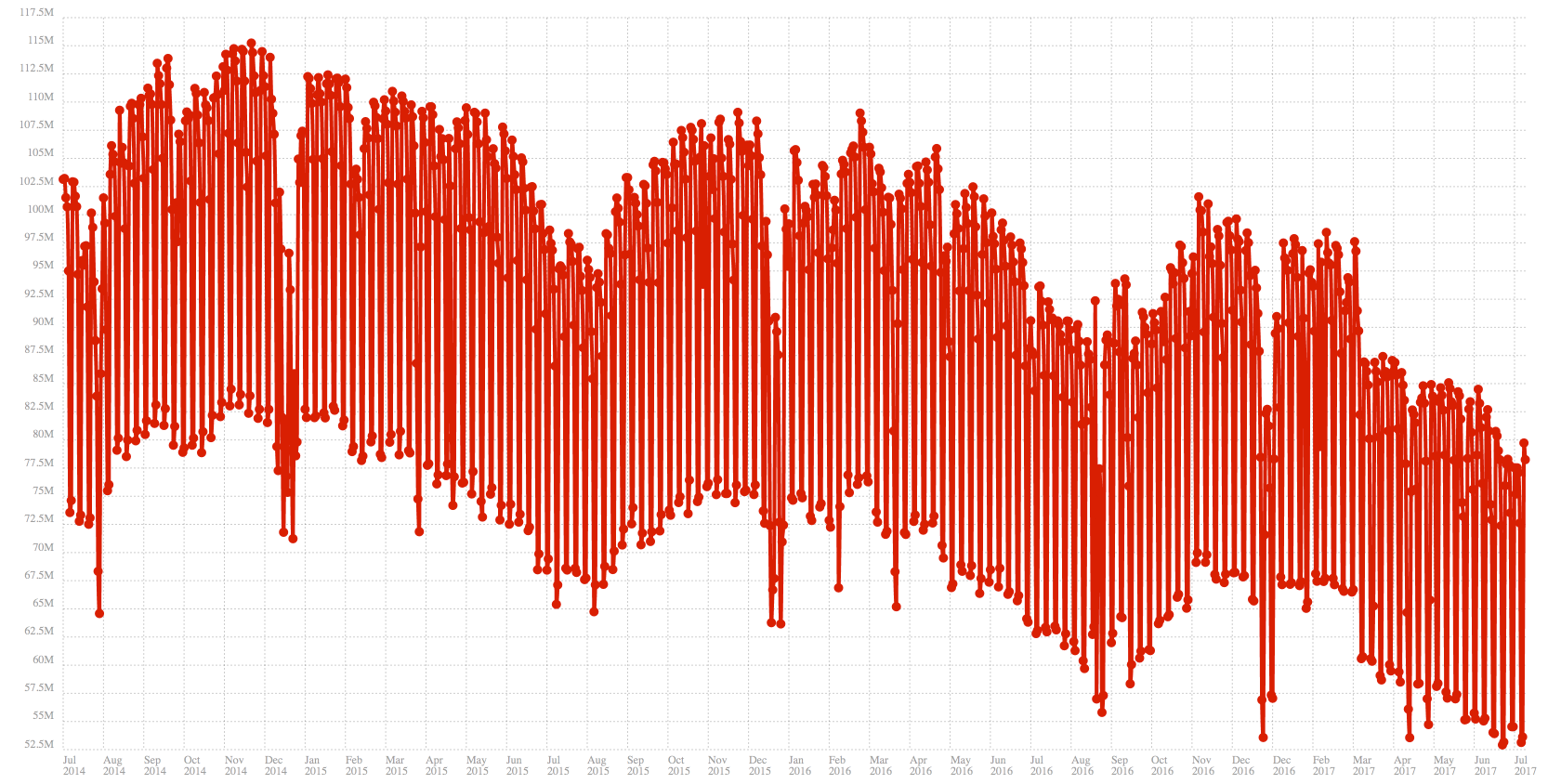
Desktop Firefox Daily Active Installs. The Y axis is not zero-based. Click on the graph to enlarge.
During any given week the ADI number can vary substantially. For the last week the peak was around 80 million users and the low was around 53 million users. To understand why the data is so variable it’s necessary to understand how Active Daily Installs are calculated.
Firefox tries to contact Mozilla once a day to check for security updates. This is called the “updater ping”. The ADI number is the aggregate number of these pings that were seen on a given day and can be understood as the number of running Firefox installs on that day.
The main reason that ADI data is so noisy is that work machines are switched off on the weekend. Those Firefox installs don’t check over the weekend, so the ADI number drops significantly. This also explains why ADIs don’t map 1:1 to Active Daily Users (ADUs). A user may be briefly active on a given day but then switches off the machine before Firefox had a chance to phone home. The ADI count can miss this user. Inversely, Firefox may be active on a day but the user actually wasn’t. Mozilla has a disclaimer on the site that publishes ADI data to point out that ADI data is imprecise, and from data I have seen actual Active Daily Users are about 10% higher than ADIs but this is just a ballpark estimate.
The graphs above also only look at the most recent version of Firefox. A subset of users are often stranded on older versions of Firefox. This subset tends to be relatively small since Mozilla is doing a good job these days converting as many users as possible to the most recently/most secure/most performant version of Firefox.
The first graph in this post was obtained by sliding a 90 day window over the data and comparing for each 90 day window the total number of active daily installs to the 90 day window a year prior. This helps eliminate some of the variability in the data and shows are clearer trend. In addition to weekly swings there is also a strong seasonality. College students being on break and people spending time with family over Christmas are some of the effects you can see in the raw data that the sliding window mechanism can filter to a degree.
If you want to explore the data yourself and see what effect shorter window parameters have you can use this link. If you see any mistakes or have ideas how to improve the visualization please send a pull request.
What about Mobile?
Mozilla doesn’t publish ADI data for Firefox for iOS and Firefox Focus, but since none of these appear in any browser statistics it means their market share is probably very small. ADI data is available for Firefox for Android and that graph looks quite a bit different from Desktop:

Firefox for Android Active Daily Installs. The Y axis is not zero-based. Click on the graph to enlarge.
Firefox for Android has been growing pretty consistently over the last few years. There is a big drop in early 2015 which is likely when Mozilla stopped support for very old versions of Android. The otherwise pretty consistent albeit slow growth seems to have stopped this year but it’s too early still to tell whether this trend will hold.
As you can see ADI data for mobile is not as noisy as desktop. This makes sense because people are much less likely to switch of their phones than their PCs.
Why?
A lot of commenters asked why Firefox marketshare is falling off a cliff. I think that question can be best answered with a few screenshots Mozilla engineer Chris Lord posted:




Google is aggressively using its monopoly position in Internet services such as Google Mail, Google Calendar and YouTube to advertise Chrome. Browsers are a mature product and its hard to compete in a mature market if your main competitor has access to billions of dollars worth of free marketing.
Google’s incentives here are pretty clear. The Desktop market is not growing much any more, so Google can’t acquire new users easily which threatens Google’s revenue growth. Instead, Google is going after Firefox and other browsers to grow. Chrome allows Google to lock in a user and make sure that that user heads to Google services first. No wonder Google is so aggressively converting everyone to Chrome, especially if the marketing for that is essentially free to them.
This explains why the market share decline of Firefox has accelerated so dramatically the last 12 months despite Firefox getting much better during the same time window. The Firefox engineering team at Mozilla has made amazing improvements to Firefox and is rebuilding many parts of Firefox with state of the art technology based on Mozilla’s futuristic rendering engine Servo. Firefox is today as good as Chrome in most ways, and better in some (memory use for example). However, this simply doesn’t matter in this market.
Firefox’s decline is not an engineering problem. Its a market disruption (Desktop to Mobile shift) and monopoly problem. There are no engineering solutions to these market problems. The only way to escape this is to pivot to a different market (Firefox OS tried to pivot Mozilla into mobile), or create a new market. The latter is what Brendan’s Brave is all about: be the browser for a better less ad infested Web instead of a traditional Desktop browser.
What makes today very different from the founding days of Mozilla is that Google isn’t neglecting Chrome and the Web the way Microsoft did during the Internet Explorer 6 days. Google continues to advance Chrome and the Web at breakneck pace. Despite this silver lining it is still very concerning that we are headed towards a Web monoculture dominated by Chrome.
What about Mozilla?
Mozilla helped the Web win but Firefox is now losing an unwinnable marketing fight against Google. This does not mean Firefox is not a great browser. Firefox is losing despite being a great browser, and getting better all the time. Firefox is simply the victim of Google’s need to increase profit in a relatively stagnant market. And it’s also important to note that while Firefox Desktop is probably headed for extinction over the next couple years, today it’s still a product used by some 90 million people, and still generating significant revenue for Mozilla for some time.
While I no longer work for Mozilla and no longer have insight into their future plans, I firmly believe that the decline of Firefox won’t necessarily mean the decline of Mozilla. There is a lot of important work beyond Firefox that Mozilla can do and is doing for the Web. Mozilla’s Rust programming language has crossed into the mainstream and is growing steadily and Rust might become Mozilla’s second most lasting contribution to the world.
Mozilla’s engineering team is also building a futuristic rendering engine Servo which is a fascinating piece of technology. If you are interested in the internals of a modern rendering engine, you should definitely take a look. Finding a relevant product to use Servo in will be a challenge, but that doesn’t diminish Servo’s role in pushing the envelope of how fast the Web can be.
And, last but not least, Mozilla is also still actively engaged in Web standards (WebAssembly and WebVR for example), even though it has to rely more on good will than market might these days. The battle for the open web is far from over.
