We have landed!
For the last two months I have been working with Mozilla on a just-in-time compiler for the JavaScript engine in Firefox, and a few hours ago this project (codenamed TraceMonkey) has landed in the main Firefox development tree.
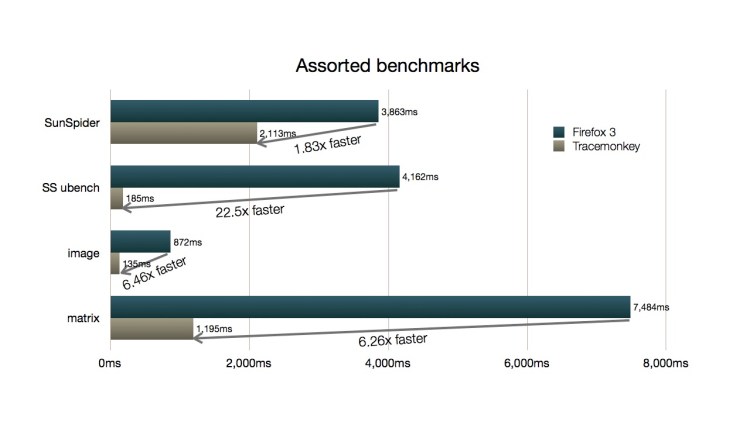
TraceMonkey is a trace-based JIT compiler and it pushes the envelope on JavaScript performance. On average, we speed up Apple’s popular SunSpider benchmarks by factor 4.6 over the last release of Firefox. The overall runtime of SunSpider improved by about 1.83x (parts of SunSpider excercise things like the regular expression engine which is outside of the scope of JIT compilation, hence the lesser overall speedup). For the SunSpider ubench suite, which focuses on core JavaScript language features, we achieve a speedup of 22x. Whichever metric you chose to apply, Firefox now has the fastest JavaScript engine in the world.
TraceMonkey Performance relative to Firefox 3.0
Mike Schroepfer put together a demo showing the real-world performance impact of TraceMonkey. You should also check out Brendan Eich’s and Mike Shaver’s blog post about TraceMonkey, as well as David Anderson’s updates on our 64-bit x86 port (yes, we do 64-bit!).
Dynamic Compilation with Traces
Traditional just-in-time compilers (like Sun’s Hotspot VM) are in their design and structure very similar to static compilers (like GCC). They observe which methods get executed frequently, and translate the method into native machine code once a certaint threshold has been reached. While such methods often contain performance-critical parts (such as loops), they often also contain slow paths and non-loopy code, which barely if at all contributes to the runtime of the method. A whole-method compiler, however, has to always analyze and translate the entire method, even if parts of it are not particularly “compilation-worthy”.
Trace-based compilation takes a very different approach. We monitor the interpretation of bytecode instruction by the virtual machine and scan for frequently taken backwards branches, which are an indicator for loops in the underlying program. Once we identify such a loop start point, we follow the interpreter as it executes the program and record the sequence of bytecode instructions that get executed along the way. Since we start at a loop header, the interpreter will eventually return to this entry point once it completed an iteration through the loop. The resulting linear sequence of instructions is what we call a trace.
Traces represent a single iteration through a loop, and can span multiple methods and program modules. If a function is invoked from inside a loop, we follow the function call and inline the instructions executed inside the called method. Function calls themselves are never actually recorded. We merely verify at runtime that the same conditions that caused that function to be activated still hold.
Trace Trees and Nested Trace Trees
TraceMonkey uses a particular flavor of trace-based compilation which I described in my dissertation: Trace Trees. Loops often consist of more than a single performance-relevant path, and Trace Trees allow to capture all of these and organize them in a tree-shaped data structure which can be compiled trace-by-trace yet produces a globally optimized result for the entire loop. To deal with nested loop, these trees can also be nested inside of each other, with outer loop trees calling the inner loop tree.

Control-Flow Graph representation of a loop with a nested condition.

Trace Tree for the code shown int he Control-Flow Graph. Traces are recorded starting at the loop header (A) and connect back to A after completing an iteration.
A particular advantage of Trace Trees is the fact that they always represent a loop and thus enter function frame and leave function frame operations are always balanced as long we stay on trace. Thus, we can actually completely optimize away the overhead of function calls. As long we stay on trace (which in case of a loop we usually do for many iterations), we don’t construct and destroy function frames. Instead, we simply execute the inlined trace we recorded. Function frames for inlined calls are only constructed should we detect that we have to leave the trace (for example because we reached the end of the loop).
Type Specialization
Trace Trees by their very nature are the result of a control-flow speculation. We speculate that loops tend to execute the same sequence of instructions over and over, which is usually true for many applications. In TraceMonkey we go a step further and also speculate on types.
JavaScript in contrast to Java or C/C++ is a dynamically typed language. Variables are declared by name only, and their type will be determined automatically once a value is assigned to them. Assigning values with different types to a variable changes the type of the variable on the fly to match the new value’s type. Executing such dynamically typed code has been traditionally fairly expensive. Type specialization eliminates much of this overhead.
Mike Shaver ran some benchmarks, comparing the performance of simple loops written in JavaScript and C. Our JIT generates code that is roughly equivalent to the performance of unoptimized C code (gcc -O0). We achieve this through aggressive type speculation. Whenever we see a program assign only integers to a variable, for example, we specialize the generated machine code to hold that variable in an integer machine register. Guards in the traces ensure that the type doesn’t unexpectedly change, in which case we leave the trace and let the interpreter handle this (unexpected and often infrequent) case.
Type specialization removes much of the principal overhead associated with dynamically typed languages, and as we further improve our JIT we expect to get fairly close to the performance of statically typed languages such as Java or C.
Traces Everywhere
Our work on TraceMonkey was done in close collaboration with Adobe’s Tamarin Tracing project. In fact, TraceMonkey and Tamarin Tracing share the same core tracing backend (nanojit), which was contributed by Adobe. Adobe has been criticized in the last few month for the slow performance of Tamarin Tracing on untyped JavaScript code. However, Tamarin Tracing is first and foremost a JIT compiler for ActionScript, a typed JavaScript dialect. While Tamarin Tracing does run untyped code, its not particularly optimized (yet) for this task.
TraceMonkey shows the full potential of Adobe’s nanojit backend when combined with a VM that was specifically designed and optimized for untyped JavaScript code (SpiderMonkey), and we expect much of our work to make its way into nanojit and Tamarin Tracing.
People
TraceMonkey was a tremendous group effort of a large group of extremely talented people. Much of the recent advances in the area of nested trees, aggressive type speculation and runtime type inference are based on work done by graduate students at our research group at UC Irvine (Michael Bebenita, Mason Chang, Marcelo Contra, Gregor Wagner and others). Our research was generously funded by a grant from the National Science Foundation (Principal Investigator Professor Michael Franz, Program Director Dr. Helen Gill) as well as grants and donations from Microsoft, Sun Microsystems, Intel, and last but not least Mozilla.
For me, it has been an amazing opportunity to spend the last two month here at Mozilla, turning our research ideas into actual product code. Its hard to describe what it feels like to work alongside people like Brendan Eich, the inventor of JavaScript, or Mike Shaver, Mozilla’s new VP Engineering and life-long JavaScript VM veteran. And even interns around here are rocket scientists. David Anderson, one of Mozilla’s interns, wrote a complete 64-bit backend for us over the summer, making TraceMonkey the first JavaScript JIT capable of targeting x86-64.
TraceMonkey was developed in close collaboration with Edwin Smith and his Tamarin Tracing team at Adobe, and the web at large owes Adobe a great deal of gratitude for open-sourcing the Tamarin and Tamarin Tracing VMs, allowing Mozilla to build TraceMonkey on top of Tamarin Tracing’s nanojit backend. nanojit is a small and highly efficient trace-based just-in-time compiler backend that is language agnostic and highly portable, and I think it has a bright future. It has just landed in Firefox, and hopefully we will see it pop up in a future release of Adobe’s Flash Player soon.
The Road Ahead
Landing in the central Firefox repository was a big step for us, but there is also definitively a lot of work ahead of us. We are now at the point where we trace a lot of code in benchmarks and on the web, but there is a lot more coverage we will add over time.
Also, we are far away from having exhausted all the potential of trace compilation and we plan to add many features and optimizations over the next few month. Our current speedups are just the beginning of whats possible:
- Improve register allocation and code generation in nanojit.
- Runtime analysis of builtins (machine code) to reduce spill overhead of builtin calls (Gregor Wagner from UCI did some work on this recently.)
- Bring performance of the ARM backend up to par with x86 and x86-64 backends and add a PowerPC backend (joint work with Adobe).
- Add tree-recompilation and parallel compilation (based on our prior work on Parallel Dynamic Compilation, Mohammad Haghighat from Intel has been looking into this for nanojit).
- Add more advanced trace optimization techniques like Tree Folding, Load Propagation and Escape Analysis.
Our goal is to eventually close the performance gap between JavaScript and traditional desktop languages, and we believe that for many applications this will be possible.
In parallel to our work with Mozilla on JavaScript performance, we also have a number of exciting tracing-related projects going on at UC Irvine. Mason Chang, one of our graduate students, is currently working with Adobe on the Tamarin Tracing VM, adding context threading and trace visualisation. Michael Bebenita from UCI is currently interning with Sun Microssystems and has been making great progress integrating our Java trace compiler into Maxine, and we plan on switching to Maxine as our main research platform for Java compilation. Alexander Yermolovich (also UC Irvine) is working with Adobe this summer on an exciting project involving fast execution of rich dynamic content that Adobe will hopefully announce to the public soon.
If you are interested in their work, check out their blogs (linked from my website). For further reading material on traces and trace compilation you can also take a log at my earlier blog posts on this topic.
Update: Mason Chang did some benchmarks comparing TraceMonkey to Apple’s WebKit/SquirrelFish VM. Looks like we are on average 2.5x faster than SquirrelFish (about 15% faster on total runtime).
I am looking for a tenure-track faculty position for Fall 2009 to continue my research on virtual machines, dynamic compilation and type-safe languages.
